
La data est comme l’anneau de Sauron : celui qui la détient possède le pouvoir. Les organisations traditionnelles ont ainsi pu contrôler les citizen dev, en leur laissant les restes, c’est-à-dire des bases Access instables et des fichiers csv sur des share windows.
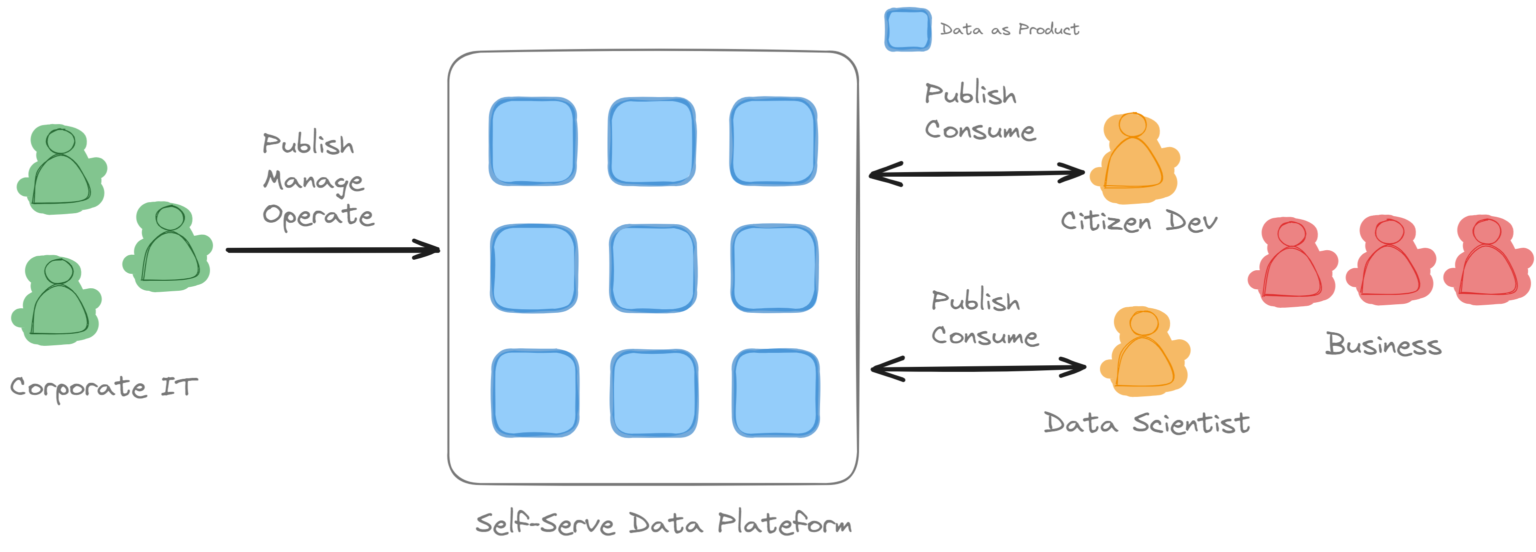
Self-Serve Data plateform
La brique technologique fondatrice d’UCD est une plateforme data en libre service, ouverte à tous et donc particulièrement aux Citizen Dev.
Dans cette nouvelle animation, la data devient un bien commun grâce à la mise en place d’une plateforme self-service mettant à disposition l’univers complet des Data as Product.
La donnée disponible pour tous, sécurisée, surveillée et monétisée doit s’imposer irréfragablement.
Sécurisé, car il faut bien entendu préserver les règles d’accès, GDPR, PII, secret des affaires, propriété intellectuelle.
Surveillé, car l’on veut savoir d’où vient la donnée, qui la consomme et comment elle est distribuée.
Enfin monétisée, car rien n’est gratuit dans ce monde et montrer au consommateur le coût réel pour une entreprise mettra en évidence la valeur des données et l’encouragera à un usage plus réfléchi et responsable de celles-ci.
La brique technologique fondatrice d’UCD est une plateforme data en libre service, ouverte à tous et donc particulièrement aux Citizen Dev. Sans cela UCD ne peut être mise en place.

Si vous êtes dans une culture Data Mesh ou Data Fabric vous devez certainement déjà avoir une plateforme en libre service. Souvent il manque juste un dernier geste… la rendre disponible aussi aux citizen dev.
Si vous n’avez rien en place, un outil de data virtualisation comme denodo pourra grandement vous faciliter la tâche pour construire cette plateforme self-service.
Un autre point d’encrage est la Read Data Stores (RDS) Architecture de Piethein Strengholt, il en développe la mise en œuvre dans son ouvrage Data Management at Scale, 2nd Edition
Data as product
Aujourd’hui le data as product, sa gouvernance et l’approche self service rattachée ont été richement portés par le data Mesh de Zhamak Dehghani https://martinfowler.com/articles/data-mesh-principles.html.
Notre but dans cet article n’est pas de rentrer en détail sur ces éléments, mais de nous concentrer sur ce qui pour un citizen dev est le plus important.
Pour une question de simplicité :
Le citizen dev va s’attendre à ce que la donnée soit facilement découvrable (discoverability). Ainsi il faut que l’entreprise, via son bras armé technologique mette en place un catalogue web qui regroupe tous les data as product. Comme expliqué dans le Data Mesh, il doit pouvoir être en contact et donc connaître via ce catalogue le domain data product owner, qui pourra répondre rapidement à ses questions.
Le citizen dev part du principe que la donnée qu’il reçoit est fiable et digne de confiance (trustworthiness). Il ne se soucie guère des questions de data quality, ce n’est pas son métier.
Pour une question d’indépendance :
Le citizen dev s’attend à pouvoir comprendre facilement la modélisation mise en place (understandability). Le vocabulaire utilisé doit être au plus proche de son expérience métier. Le Domaine Driven Design (DDD) reste invariablement la bonne approche de modélisation.
Le citizen dev doit pouvoir accéder à la donnée sans dépendance directe avec l’IT. Cela n’exclut pas la mise en place d’une gouvernance, mais celle-ci doit rester minimaliste et portée par un organe métier. La sécurité bien que nécessaire doit être la plus transparente possible pour lui.
Pour une question de self improvement :
Le citizen dev doit régulièrement être formé sur les avancées de la plateforme self service. Aussi bien technologiquement que fonctionnellement. Dans la pratique on se rend compte bien souvent qu’un citizen n’est pas assez formé sur la donnée. S’il ne doit pas avoir besoin de comprendre finement ce qu’est un data as product, il doit au moins saisir les trois limites du dataset.
Est ce que l’univers de ce dataset contient toutes les entités dont j’ai besoin ? Par exemple y a-t-il bien dans le data as product Article, tous les articles vendus en Asie ?
Est ce que mon data as product contient tous les champs dont j’ai besoin ?
Enfin, quel est le niveau de fraîcheur de la donnée que je vais récupérer ?
En 2025 coupler naïvement son LLM à sa plateforme data pour répondre aux besoins précédent ne fonctionne pas.
Le data as product devient la première zone d’excellence des équipes software, sa testabilité, sa modélisation, ses metadatas, sa gouvernance, sa sécurité, son support, sont la condition sine qua non au succès de la démocratisation du citizen dev. Ils sont portés comme le montre le diagramme précédent par une plateforme self-service.
{kind=link}
API / Get seulement
Nous mettons les API dans la partie data, car nous nous concentrons sur une perspective de consommation et de distribution. Nous parlerons bien entendu plus tard des API pour la partie modification via le CQRS.
Idéalement les APIs en lecture seule devraient être montées directement sur les data as product, rendant la chose totalement inutile pour le citizen dev car ils peuvent directement accéder au dataset.
Cependant il arrive quelquefois qu’une seule API soit disponible. Soit parce que le système opérationnel offre un niveau de fraîcheur non supportable par la plateforme self-service, soit parce que nous avons affaire à un logiciel acheté.
Bien entendu un citizen dev est toujours à même de consulter une API. Cela demande plus de travail, surtout si la donnée doit être jointe ou agrégée. Cependant l’approche que nous préconisons est d’utiliser un outil de data virtualisation (Denodo, TIBCO Data Virtualization, etc.). En virtualisant l’API sous la forme d’une base de données, le citizen ne fera pas la différence avec un autre data as product.
Streams / Motion
Le ballet de données qui circulent par événement ou par message est extrêmement difficile à manipuler pour un citizen dev. L’IT devra mettre en place des couches de persistances secondaires, structurées. On évitera les event store.
Modification Traitement
Le citizen dev veut et doit pouvoir intervenir sur le système d’information. A titre informatif, il veut pouvoir être notifié automatiquement, générer des rapports internes, opérer des modifications sur des données signalétiques, produire ses ensembles de données, passer des paiements automatiquement, régler les factures, orchestrer des traitements, etc.
Autant que possible, il doit pouvoir exécuter ces actions sans écran ou logiciel spécifique.
Un éventail d’API
Le catalogue d’APIs de l’entreprise doit permettre au citizen dev de connaître toutes les opérations qu’il peut effectuer. Tout comme pour la Data, il ne devrait pas y avoir de distinction entre l’IT Corporate et les citizen dev.
Une API d’entreprise est par définition pour toute l’entreprise.
Si ces transformations sont du type CRUD, le citizen dev opère cela directement sur le data product en accord de toute façon avec ses ACLs. Il pourra être aidé par son référent IT (Athena) pour écrire sa requête ou faire appel à un LLM.
Pour des opérations plus avancées, une approche commande sera préconisée. En fait nous la conseillons même pour les actions plus simples comme décrit précédemment. Nous adoptons ici avec ferveur une démarche CQRS. Nous modifions par des commandes envoyées à des APIs, nous consultons par des requêtes SQL sur data as product :

N’oublions pas ici que les data as product et les APIs sont les résultats d’un travail de haute expertise offert par l’IT.
Bref, en utilisant les commandes, nous offrons aux citizen dev un vocabulaire métier, une protection d’usage pour le SI et une indépendance technologique dans les stratégies de persistance des systèmes opérationnels. En contrepartie, une complexité supérieure d’intégration doit être gérée par le citizen dev.
Maintenant que nous avons fait le point sur la data il est temps de nous intéresser aux Graphical User Interface (GUI) du citizen dev
Leave a Reply